09. Split Dataset for Model Development
Split Dataset for Model Development
ND320 C2 L3 09 Splitting Your Dataset For Model Development Walkthrough
Note: the train_test_split package comes from a sklearn package: sklearn.model_selection.train_test_split
Split data using train_test_split with Sklearn

Summary
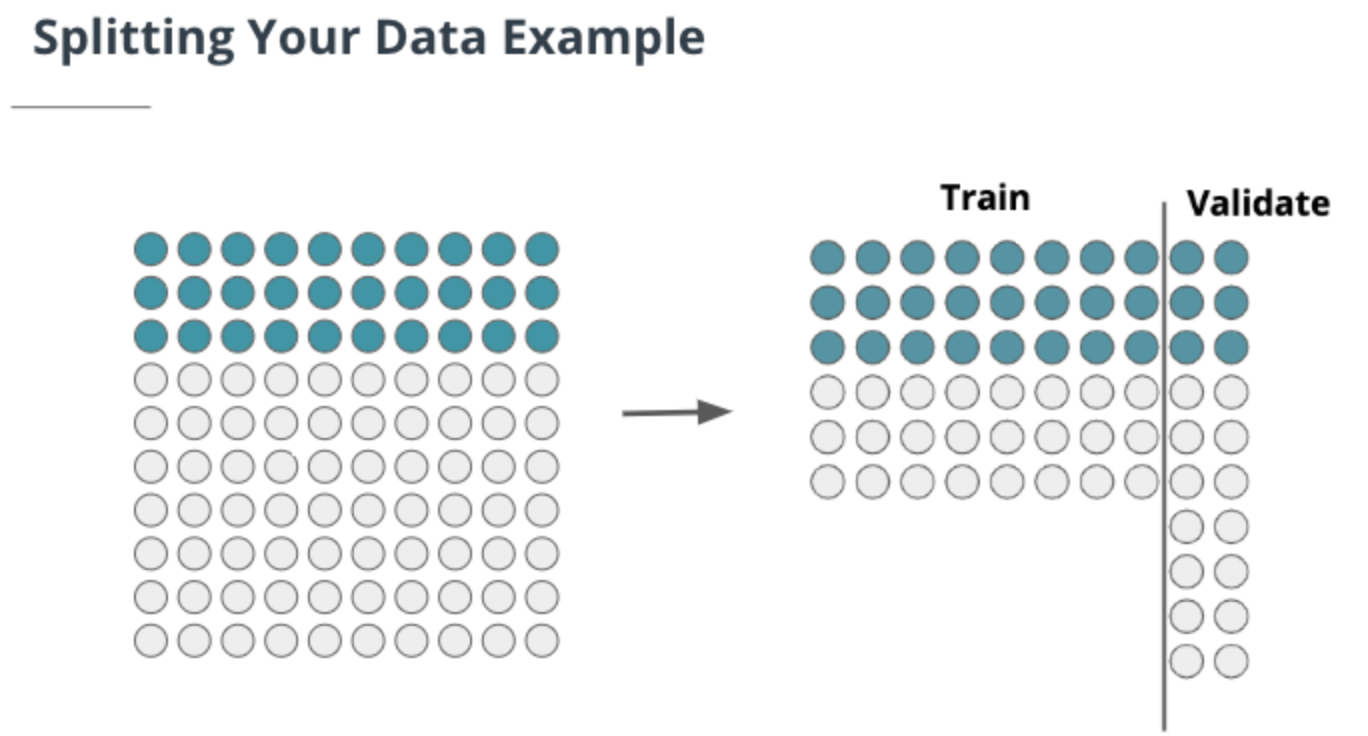
You need to split your data into two sets before feeding it into the model.
- A training set: DL algorithm will use this data to learn the features that differentiate between your classes.
- A validation set: the algorithm will never use this set for learning. This is the set to determine if the algorithm is actually learning to discriminate between your classes.
The general rule of thumb is to split your data 80 in the training set and 20 in the validation set. The data should be split to maximize the prevalence of positive cases (i.e make sure 80% of your positive cases end up in the training set and 20% in the validation set).
We want to have a balanced training set so that the model has an equal number of cases in each class to learn. Even if one class is really rare in the wild. We want to have an imbalanced validation set to reflect the real-world situation.
For all other variables in your dataset such as age, sex, and race, the distribution should follow the same distribution as your original full dataset.
Note: an image should NEVER be used for both training and validation.